chatgpt 提升开发效率

近期ChatGPT可以说是火遍了全世界,作为由知名人工智能研究机构OpenAI于2022年11月30日发布的一个大型语言预训练模型,他的核心在于能够理解人类的自然语言,并使用贴近人类语言风格的方式来进行回复。
模型开放使用以来,在人工智能领域引起了巨大的轰动,也成功火出了技术圈。从数据上看,ChatGPT用户数在5天内就达到了100万,2个月就达到了1亿;另外,在很多非人工智能领域,已经有机构在尝试用ChatGPT去做一些智能生成的事。例如财通证券发布了一篇由ChatGPT生成的行业研报,从研报的可读性和专业性上来看,虽然在细节上有很多需要推敲的地方,但是整体框架内容已经比较成熟。对于其他内容生产者来说,应用ChatGPT也能够提升个人的生产效率。
ChatGPT是什么?
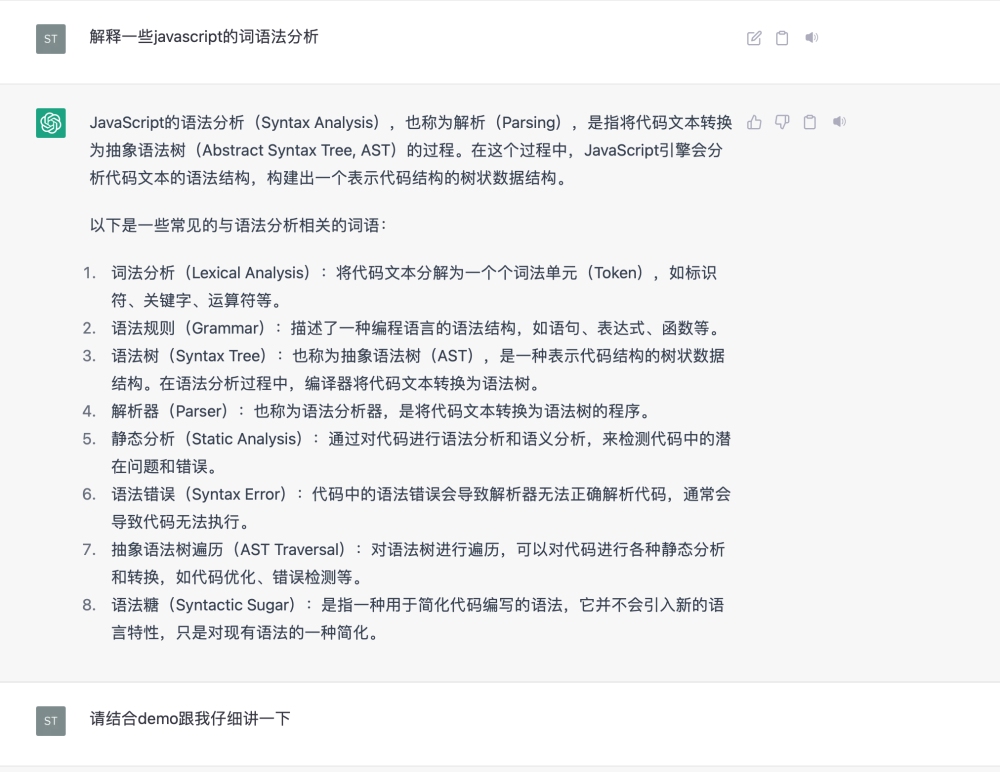
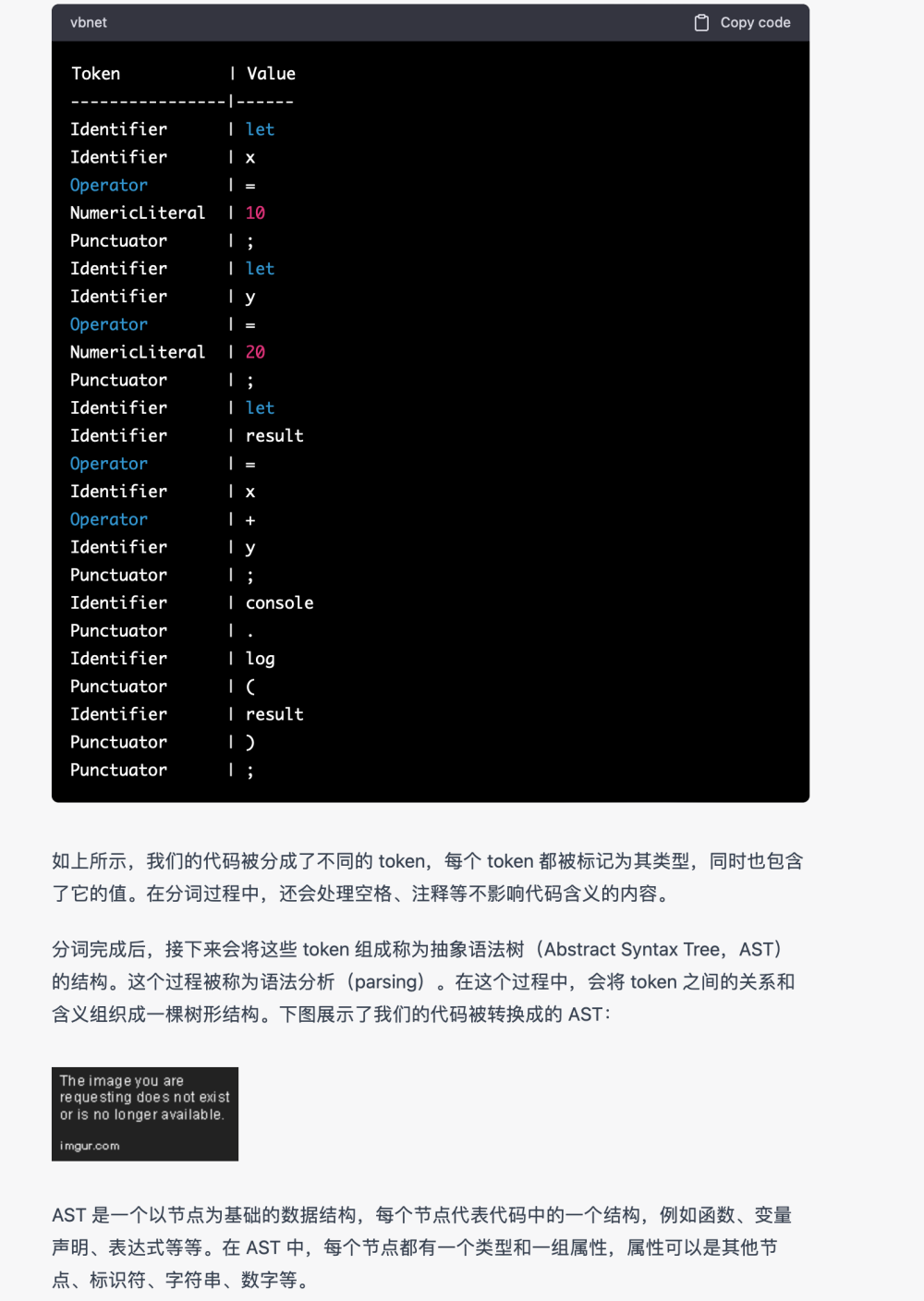
上文说到ChatGPT实际上是一个大型语言预训练模型(即Large Language Model,后面统一简称LLM)。什么叫LLM?LLM指的是利用大量文本数据来训练的语言模型,这种模型可以产生出强大的语言关联能力,能够从上下文中抽取出更多的信息。其实语言模型的研究从很早就开始了,随着算力的发展和数据规模的增长,语言模型的能力随着模型参数量的增加而提升。下图分别展示了LLM在参数量和数据量上的进化情况,其中数据量图例展示的是模型在预训练过程中会见到的token数量,对于中文来说一个token就相当于一个中文字符。
—摘抄自知乎”邱震宇“老师的话。
助力研发
就目前来看一个没有经过刻意训练的GPT可以从以下几个方面协助开发提升开发效率。
代替搜索引擎
errorCode:”multiple matching tokens
想象一个这样的场景,一个线上的前端项目客户在控制台中发现了一个报错,集成过”@azure/msal-browser”类库,且做过aad认证开发的人都会看出来这是一个关于”@azure/msal-browser”的报错
errorMessage: “The cache contains multiple tokens satisfying the requirements.Call AcquireToken againproviding more requirements such as authority or account..’ line: 93
message: “multiple_matching_tokens: The cache contains multiple tokens satisfying the requirements Call AcquireToken again providing more requirements such as authority or account..” name:”ClientAuthError”
这个时候我们会拷贝这个错误,在google 或者 百度,或者@azure/msal-browser官方文档/github issue 中去寻找相关的解决方案,因为我们并不熟悉这个类库的内部细节.
1.使用google
经过我们过滤,觉得第一个应该是我们需要的链接
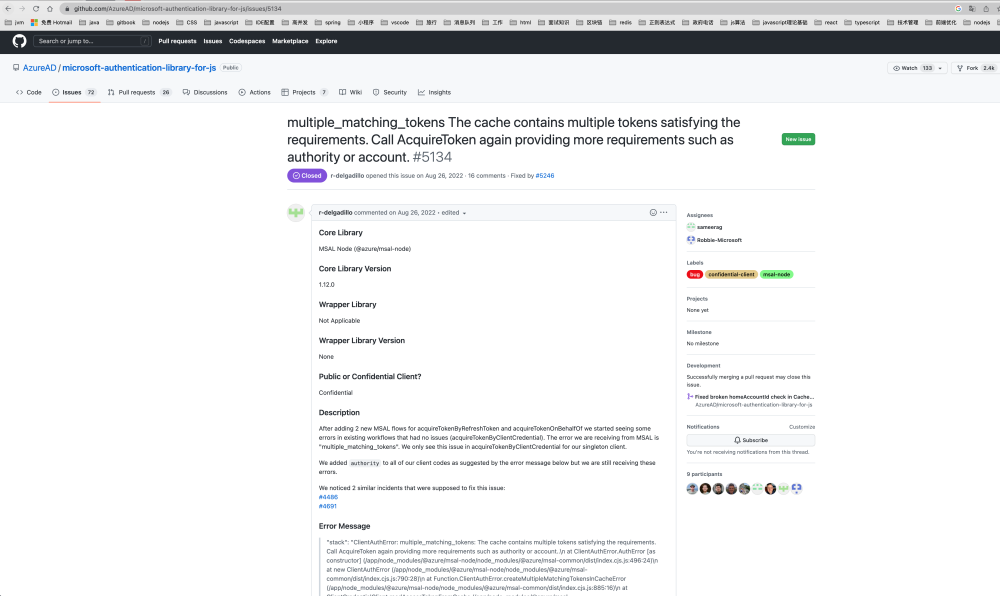
确实 我们发现这个这个issue跟我们遇到的问题一样,然后我们继续在评论和回答中寻找解决方案,但是 其实这个页面上并没有找到最终的解决办法,最终的解决方式是通过源码定位到了这个问题。
2.GPT
下面让我们来做一个测试

以下是一个简单的示例代码,用于在 MSAL.js 中处理缓存中存在多个令牌的情况:
const msalConfig = {
auth: {
clientId: "your_client_id",
authority: "https://login.microsoftonline.com/your_tenant_id",
redirectUri: "http://localhost:3000" // your app redirect uri
},
cache: {
cacheLocation: "localStorage",
storeAuthStateInCookie: true
}
};
const myMSALObj = new msal.PublicClientApplication(msalConfig);
const request = {
scopes: ["user.read"]
};
myMSALObj.acquireTokenSilent(request).then(function (response) {
// Use token from response
}).catch(function (error) {
if (error.name === "InteractionRequiredAuthError") {
// Redirect user to login
} else if (error.name === "ClientAuthError" && error.errorCode === "multiple_matching_tokens") {
// Handle multiple matching tokens
const tokenRequest = {
scopes: ["user.read"],
authority: "https://login.microsoftonline.com/your_tenant_id", // limit to specific authority
account: myMSALObj.getAccountByHomeId(response.account.homeAccountId) // limit to specific account
};
myMSALObj.acquireTokenSilent(tokenRequest).then(function (response) {
// Use token from response
}).catch(function (error) {
// Handle error
});
} else {
// Handle other errors
}
});
这个代码片段中,我们使用 acquireTokenSilent 函数从缓存中获取令牌,如果出现 ClientAuthError 错误且错误代码为 multiple_matching_tokens,则表明缓存中存在多个符合要求的令牌。
在这种情况下,我们可以通过指定更具体的条件来获取正确的令牌,例如通过指定 authority 和 account 参数。在成功获取到令牌后,您可以使用该令牌来调用受保护的资源。
GPT正确的给了我们解决方案,从对话上来,一共用了不到5分钟解决了这个问题。
我们可以看出,GPT不但给我们解释了这个问题的原因,还提供了demo代码,以及实现方式的解释.
辅助项目开发
项目中,不管是前端开发,还是后端开发,都会遇到些这则表达式的情况,正则表达式的语法,枯燥,而且很难记住,有时候我们直接通过搜索引擎去找,去找符合我们要求的正则表达式,但是由于业务的独特性,你很难找到合适的正则,这个时候需要你打开正则表达式的语法文档,闷头自己写。。。。
再比如后端开发再服务器查日志的时候会记不住linux命令,
再比如客户需要你提供一个业务复杂的sql,有一些函数你记不住。
1.正则表达式生成器
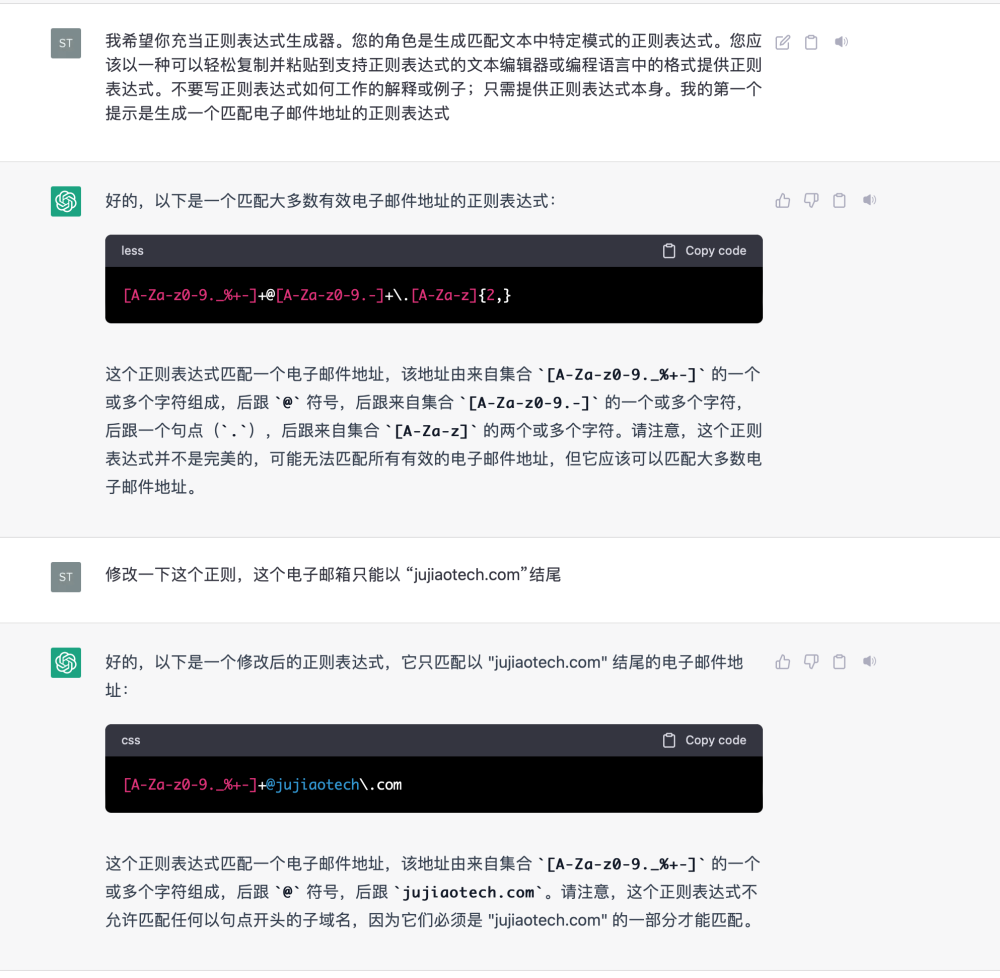
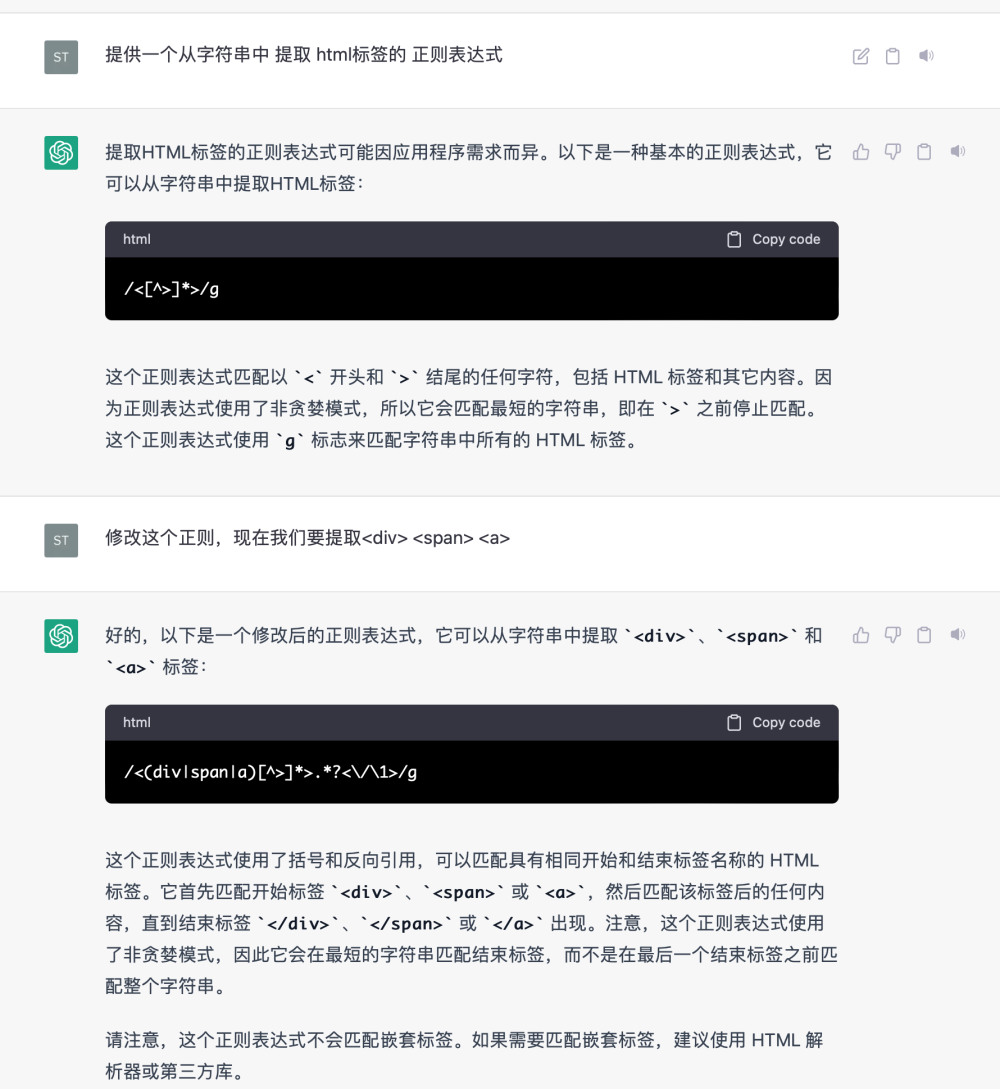
2.工具方法的的生成器

function flattenTree(treeData) {
let flattened = [];
function flatten(node, parentPath = '') {
const { id, name, children } = node;
const path = `${parentPath}/${id}`;
flattened.push({ id, name, path });
if (children) {
children.forEach(child => flatten(child, path));
}
}
flatten(treeData);
return flattened;
}
该函数将接收一个树形结构的数据,并返回一个扁平化的数组,其中每个节点都包含其 id、name 和 path 属性。 path 属性是从根节点到当前节点的完整路径。
以下是一个测试用例:
const treeData = {
id: '1',
name: 'root',
children: [
{
id: '1-1',
name: 'child1',
children: [
{
id: '1-1-1',
name: 'grandchild1'
},
{
id: '1-1-2',
name: 'grandchild2'
}
]
},
{
id: '1-2',
name: 'child2',
children: [
{
id: '1-2-1',
name: 'grandchild3'
},
{
id: '1-2-2',
name: 'grandchild4'
}
]
}
]
};
const flattenedData = flattenTree(treeData);
console.log(flattenedData);
输出结果
[
{ id: '1', name: 'root', path: '/1' },
{ id: '1-1', name: 'child1', path: '/1/1-1' },
{ id: '1-1-1', name: 'grandchild1', path: '/1/1-1/1-1-1' },
{ id: '1-1-2', name: 'grandchild2', path: '/1/1-1/1-1-2' },
{ id: '1-2', name: 'child2', path: '/1/1-2' },
{ id: '1-2-1', name: 'grandchild3', path: '/1/1-2/1-2-1' },
{ id: '1-2-2', name: 'grandchild4', path: '/1/1-2/1-2-2' }
]
3.提供开发思路
多级审批工作流
我的设计思想是基于面向对象的设计和模块化的编程思想。首先,我定义了一个工作流程节点类,用于表示每个审批节点,包含节点名称、下一级审批节点、审批角色等信息。然后,我创建了多个节点对象,将这些节点对象按照顺序连接起来,形成一个完整的审批流程。接着,我定义了一个角色-用户的映射表,用于记录每个角色对应的审批用户。在进行审批流程时,我通过循环遍历审批流程中的每个节点,根据当前节点的审批角色,从映射表中获取对应的审批用户列表,提示用户输入自己的名字进行审批。如果当前用户不属于该节点的审批用户列表,那么提示用户没有权限进行审批,直到有权限的用户进行审批或者有用户拒绝审批为止。最后,根据审批结果输出相应的信息。这种设计思想使得代码具有高可读性、可维护性和可扩展性,易于管理和更新工作流程及用户角色。
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Scanner;
public class Workflow {
//定义工作流程节点类
private static class WorkflowNode {
private final String name;
private final List<String> nextNodes; //该节点的下一级审批节点
private final String approveRole; //审批角色,即该节点需要哪个角色的用户来进行审批
public WorkflowNode(String name, String approveRole) {
this.name = name;
this.nextNodes = new ArrayList<>();
this.approveRole = approveRole;
}
public String getName() {
return name;
}
public List<String> getNextNodes() {
return nextNodes;
}
public String getApproveRole() {
return approveRole;
}
public void addNextNode(String nodeName) {
this.nextNodes.add(nodeName);
}
}
public static void main(String[] args) {
//创建工作流程节点
WorkflowNode startNode = new WorkflowNode("Start", "staff");
WorkflowNode departmentNode = new WorkflowNode("Department Manager Approval", "department manager");
WorkflowNode financeNode = new WorkflowNode("Finance Manager Approval", "finance manager");
WorkflowNode endNode = new WorkflowNode("End", "");
//将节点添加到工作流程中
startNode.addNextNode(departmentNode.getName());
departmentNode.addNextNode(financeNode.getName());
financeNode.addNextNode(endNode.getName());
//定义审批角色及其对应的用户
Map<String, List<String>> roles = new HashMap<>();
roles.put("staff", List.of("Alice", "Bob"));
roles.put("department manager", List.of("Charlie", "David"));
roles.put("finance manager", List.of("Eve", "Frank"));
//定义待审批的请求
String request = "A new project needs funding";
//进行多级审批流程
boolean approved = true;
String currentNode = startNode.getName();
while (!currentNode.equals(endNode.getName())) {
System.out.println("Request: " + request);
System.out.println("Current node: " + currentNode);
System.out.println("Approve role: " + getNodeByName(currentNode).getApproveRole());
System.out.print("Please enter your name to approve or reject (enter 'reject' to reject): ");
Scanner scanner = new Scanner(System.in);
String userName = scanner.nextLine();
if (userName.equals("reject")) {
approved = false;
break;
}
if (!roles.get(getNodeByName(currentNode).getApproveRole()).contains(userName)) {
System.out.println("You are not authorized to approve this request. Please try again.");
continue;
}
currentNode = getNodeByName(currentNode).getNextNodes().get(0); //假设每个节点只有一个下一级节点
}
//输出审批结果
if (approved) {
System.out.println("Request approved!");
} else {
System.out.println("Request rejected.");
}
}
//根据节点名称获取节点对象
private static WorkflowNode getNodeByName(String nodeName) {
WorkflowNode startNode = new WorkflowNode("Start", "staff");
WorkflowNode departmentNode = new WorkflowNode("Department Manager Approval", "department manager");
WorkflowNode financeNode = new WorkflowNode("Finance Manager")
熟悉新的领域知识
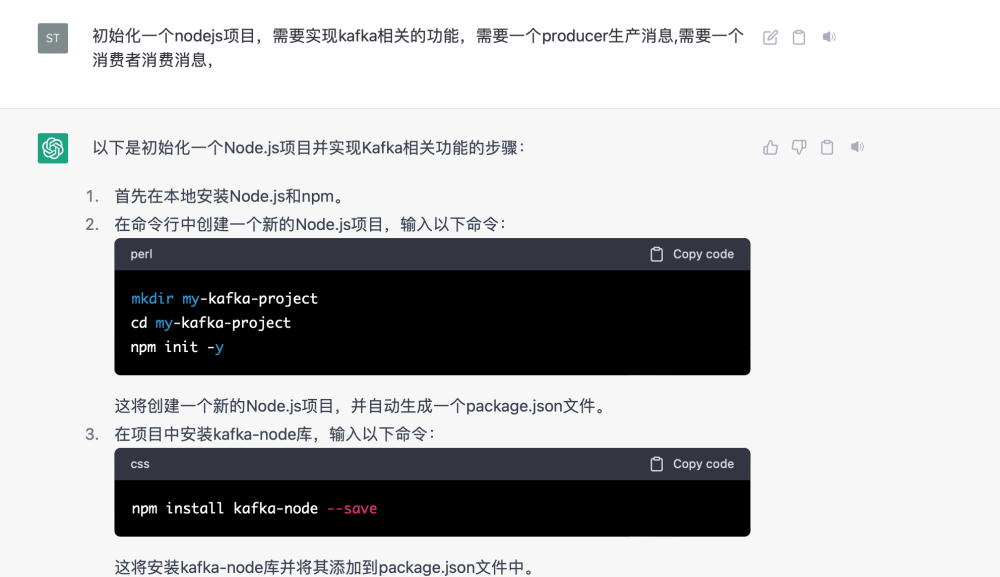
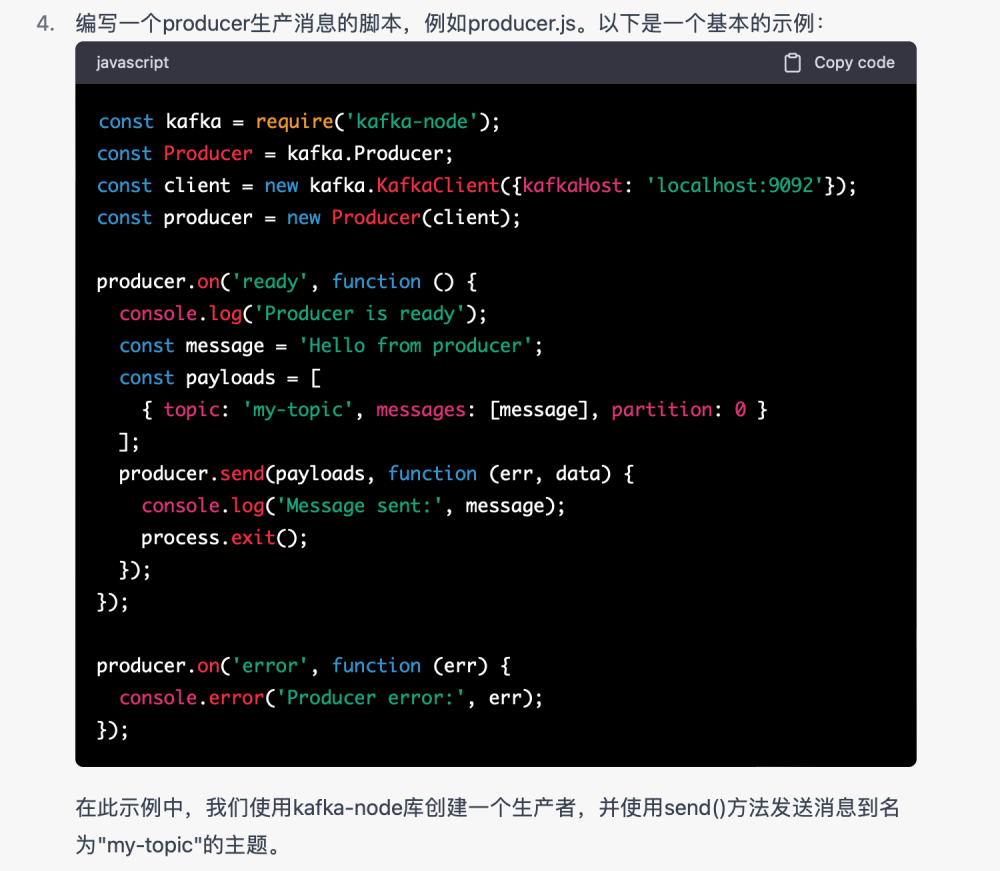
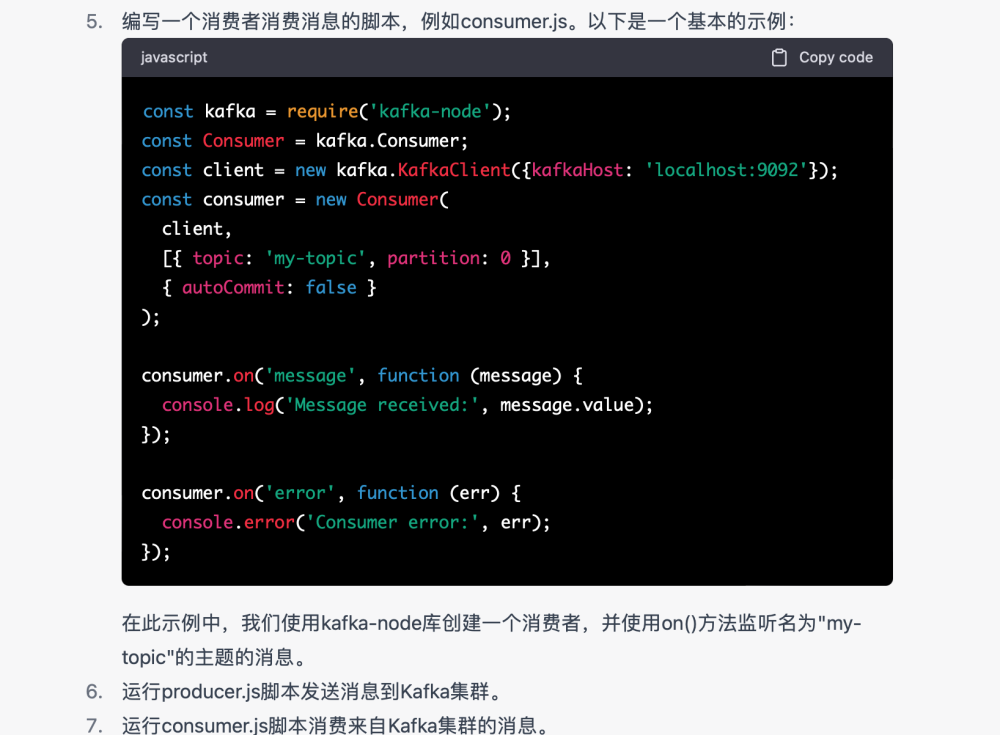
1.kafka的demo消息生产
有一个数据相关项目,里面需要集成kafkaUI的一些页面,楠姐正在研究kafkaUI,于是我们就搭建了一个kafka,但是需要一些测试数据,那问题来了,这些数据我们怎么造?我们也没有kafka相关的经验。
但是我们知道 需要用程序造这些数据,我们需要启动一个服务作为topic的消费者。
GPT帮我解决了这个问题。
2.产品经理 熟悉datahub,引用自“DataHub基础概念”
DataHub 是什么?
DataHub 是一个由 LinkedIn 开源的数据协作平台,用于管理、发现和使用企业数据。
它提供了一系列的工具和服务,帮助企业实现数据管理、数据搜索、数据协作、数据共享等功能,支持多种类型的数据源、多种数据格式和多种数据处理方式。
DataHub 的核心组件包括:
- Metadata Service:用于管理和查询数据源和数据集的元数据,支持标准化的数据源和数据集描述,提供基于关键词、分类、数据类型等多维度的搜索和发现功能。
- Data Service:用于访问和处理数据,支持多种数据源和数据格式,提供标准化的数据访问接口和数据处理流程,支持数据缓存和数据分发等功能。
- Gobblin:一个分布式的数据集成和数据处理框架,支持多种数据源和数据格式,提供标准化的数据采集、数据清洗、数据转换等功能。
- Data Portal:一个基于 Web 的数据门户,用于展示和管理数据资源,提供基于角色、权限、搜索等多种方式的数据浏览和数据访问
DataHub 的优势在于它提供了一套完整的数据管理和数据协作解决方案,能够帮助企业快速构建数据管理平台,提高数据质量和数据可用性,促进数据驱动业务决策。同时,DataHub 是一个开源项目,可以通过 GitHub 获取源代码并进行二次开发和定制。
datahub解决的核心问题
DataHub 解决的核心问题是企业数据管理和数据协作的问题。
在企业内部,数据通常散布在不同的系统、应用和部门中,且数据格式、质量、准确性等方面存在很多差异和问题,导致数据的管理、查询、访问、分享等方面面临很多挑战。DataHub 提供了一整套的数据管理和数据协作解决方案,能够帮助企业解决以下核心问题
- 数据管理:DataHub 提供了元数据服务和数据门户等功能,帮助企业标准化数据源和数据集的描述和管理,实现数据的集中化、可视化、可查询化和可控制化,提高数据的质量和可用性。
- 数据协作:DataHub 提供了数据协作平台和数据访问服务等功能,支持企业内部和企业间的数据共享和数据访问,实现数据的互通和共享,促进企业内部和企业间的数据协作和业务协同。
- 数据可靠性:DataHub 提供了数据质量管理和数据治理等功能,帮助企业发现和解决数据质量问题,规范数据使用和管理流程,提高数据的准确性、一致性和可靠性。
- 数据驱动决策:DataHub 提供了数据分析和数据可视化等功能,帮助企业深入挖掘和分析数据,发现业务价值和趋势,支持数据驱动决策。
综上所述,DataHub 的核心目标是帮助企业实现数据资产化,提高数据的质量和可用性,促进数据协作和业务创新。
使用datahub
使用 DataHub 一般需要以下步骤:
- 部署 DataHub:可以通过下载源代码编译部署,也可以使用 Docker 镜像部署。部署完成后需要进行相关配置,例如配置元数据存储和数据存储方式等。
- 创建元数据:使用 DataHub 的元数据服务可以创建数据源和数据集的元数据信息,包括数据源的类型、地址、认证方式等信息,以及数据集的名称、描述、数据格式、访问权限等信息。
- 创建数据集:使用 DataHub 的数据服务可以创建数据集并指定数据源,可以对数据集进行数据缓存和数据分发等操作。
- 使用数据集:使用 DataHub 的数据服务可以访问数据集,并进行数据处理和数据分析等操作。DataHub 提供了多种数据访问方式和数据处理流程,例如使用 SQL 查询、使用 Spark 处理、使用 Hadoop MapReduce 处理等。
- 使用数据门户:使用 DataHub 的数据门户可以浏览和搜索数据集的信息,可以查看数据集的元数据信息和数据预览等内容。数据门户还可以根据用户的角色和权限控制数据集的访问和使用。
需要注意的是,使用 DataHub 需要了解相关的概念和术语,例如元数据、数据集、数据源、数据流等。此外,DataHub 还提供了一些可选的功能,例如数据质量管理、数据治理、数据安全等,可以根据实际需求进行配置和使用。
概念和术语
当使用 DataHub 时,需要了解以下相关的概念和术语:
- 元数据(Metadata):描述数据的数据,包括数据源、数据集的名称、描述、格式、访问权限、字段信息等。在 DataHub 中,元数据存储在元数据服务中,可以通过元数据服务进行管理和查询。
- 数据源(DataSource):数据源是一种包含数据的位置或者实体,例如数据库、文件、API 等。在 DataHub 中,数据源可以是关系型数据库、Hadoop 集群、文件系统等。
- 数据集(Dataset):数据集是一组经过组织的数据,例如数据库表、CSV 文件、JSON 数据等。在 DataHub 中,数据集通常由数据源提供,可以通过数据服务进行访问和使用。
- 数据服务(Data Service):提供数据访问和数据处理的服务,例如 SQL 查询、Spark 处理、Hadoop MapReduce 处理等。在 DataHub 中,数据服务提供了多种数据访问方式和数据处理流程,可以根据实际需求进行配置和使用。
- 元数据服务(Metadata Service):提供元数据管理和查询的服务,可以创建、更新、查询数据源和数据集的元数据信息。在 DataHub 中,元数据服务是核心的管理和查询服务,可以通过 API 或者 Web 界面进行访问和操作。
- 数据门户(Data Portal):用于数据集的浏览和搜索的门户网站。在 DataHub 中,数据门户提供了数据集的元数据信息、数据预览、搜索、授权等功能,可以根据用户的角色和权限进行访问和使用。
- 数据流(Data Stream):一种数据传输和处理的方式,用于实时处理数据流。在 DataHub 中,数据流可以用于实时处理数据,例如使用 Apache Kafka 进行数据传输和处理。
- 数据缓存(Data Caching):用于加速数据访问和提高数据可用性的技术,例如使用 Redis 缓存数据。在 DataHub 中,可以使用数据缓存加速数据集的访问和提高数据的可用性。
- 数据分发(Data Distribution):用于将数据传输到不同的目标系统或应用的技术,例如使用消息队列、数据集成工具等。在 DataHub 中,数据分发可以用于将数据集分发到不同的系统或应用,例如实时数据仓库、数据分析工具等。
以上是一些常见的 DataHub 相关概念和术语,需要根据实际使用情况进行了解和学习。
数据血缘
数据血缘(Data Lineage)指的是在数据管道或数据处理过程中,数据从源头到目标端的路径或流程的可追溯性和可理解性。
数据血缘可以追溯数据的流转路径、数据来源、数据处理过程、数据存储位置等关键信息,帮助数据治理人员和数据分析师更好地理解数据的来源、质量、可用性以及对业务的影响等。
具体来说,数据血缘可以回答以下问题:
- 数据从哪里来,到哪里去?
- 数据在处理过程中经过了哪些转换和操作?
- 数据被谁和何时修改了?
- 数据质量和可用性如何保障?
- 数据与业务之间的关联和影响如何理解和管理?
数据血缘通常需要通过技术手段来实现,例如数据集成工具、数据质量工具、元数据管理工具等。同时,数据血缘也需要结合业务需求和数据治理策略进行分析和应用,以实现数据的有效管理和利用。
假设某公司使用一个数据仓库来存储各种数据,并使用 ETL 工具来实现从数据源到目标仓库的数据传输和转换。此时,如果某个分析师想要了解一个销售报告中某个数据项的来源和准确性,那么数据血缘就可以帮助他快速回答以下问题:
问:数据项从哪里来,到哪里去?
答:数据项最初来源于销售数据库中的订单信息,经过ETL工具进行了一系列的数据清洗和处理后,最终存储在数据仓库的销售报告中。
问:数据项在处理过程中经过了哪些转换和操作?
答:在数据仓库中,数据项被用于生成不同的销售报告,同时还与其他数据项进行了关联和聚合计算。
问:数据项被谁和何时修改了?
答:数据项的修改历史可以通过数据仓库或ETL工具的日志进行追踪和查询。
问:数据质量和可用性如何保障?
答:数据血缘可以帮助分析师追踪数据的来源和处理过程,同时还可以帮助监测数据质量和可用性等指标,从而提高数据的准确性和可靠性。
问:数据与业务之间的关联和影响如何理解和管理?
答:通过数据血缘,分析师可以了解数据与业务之间的关系和影响,从而更好地支持业务决策和分析。
作为自我提升的工具
他可以提供给你一些学习的资料,
你可以利用他学习一些原理性的知识,比如:当你想学习一个技术,或者想学习一个新领域,但是又没有思路的时候,你可以通过他获取一些思路。

再比如我想了解一下javascript的词语法解析